
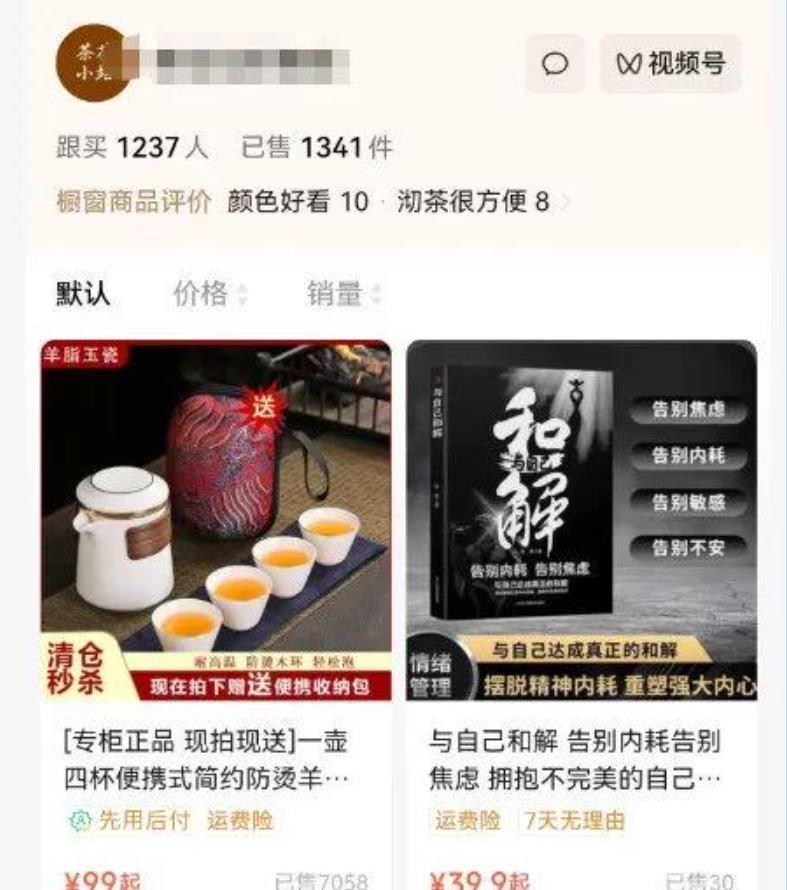
今天介绍的这个是国学文化,小肥鱼网创分享的视频混剪案例,下面是视频号的一个对比账号。


再看下其橱窗带货,真的很强。
工作流设计流程我提前放出来了

工作流搭建
首先我们定义输入,可以是你自己准备好的固定文案,也可是由模型生成,或者提取的对标视频文案。自行选择。
此处我们使用抖音链接 提取文案,具体抖音文案提取的工作流如有需要可留言评论,我安排分享计划。
然后通过文本处理节点,拆分句子
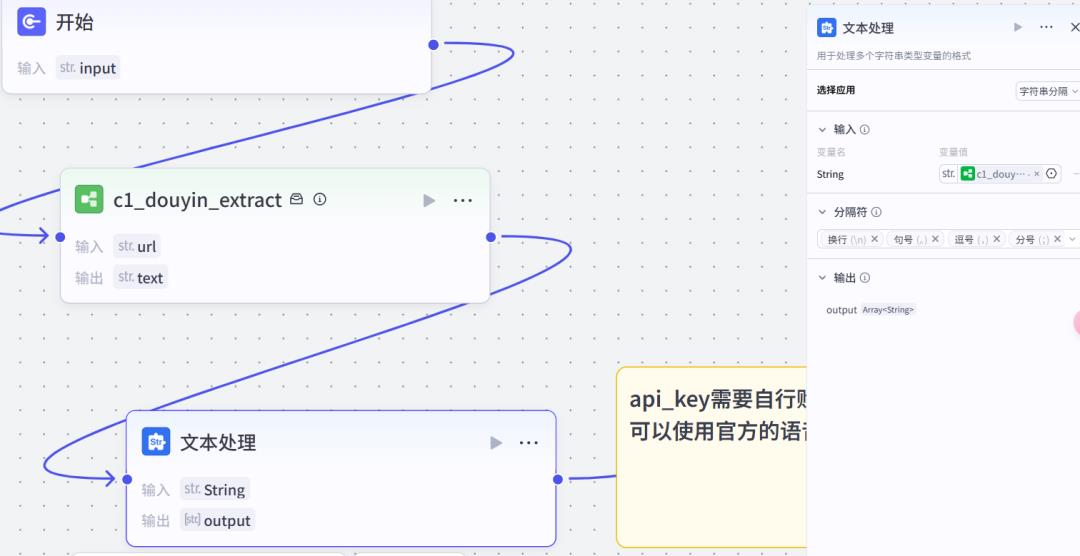
继续,使用代码节点,将分割后的数组进行转换成以换行符分割的字符串,为后续字幕对齐做准备

下一步,我们引入文本转语音插件,将文案转换成富有情感的配音。

此处使用的文本转语音插件为DubbingX付费插件。
你也可以使用官方提供的语音生成插件进行代替,可参考之前的案例中我们使用的方式。
这个插件支持非常独的音色,并且支持自己克隆音色,感兴趣的可以探索下。

老样子,使用获取音频时长插件,获取音频时间用于后续计算时间线使用。
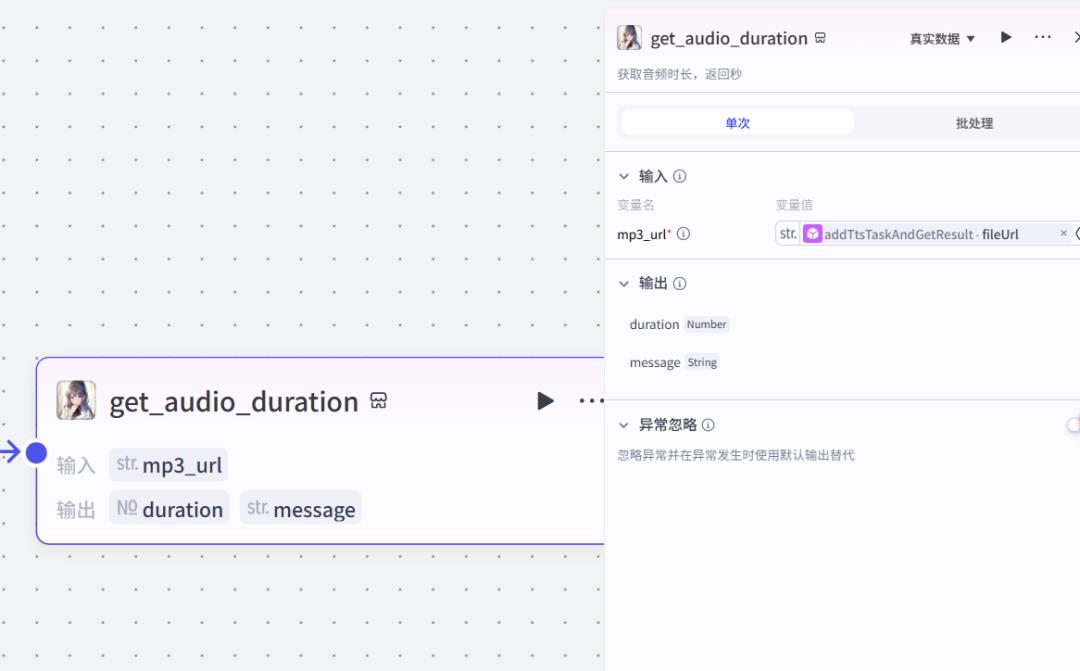
字幕与音频进行对齐,保证输出的字幕出现时间更加准确。
这里引入一个新的插件,实现字幕与音频的完美对齐。
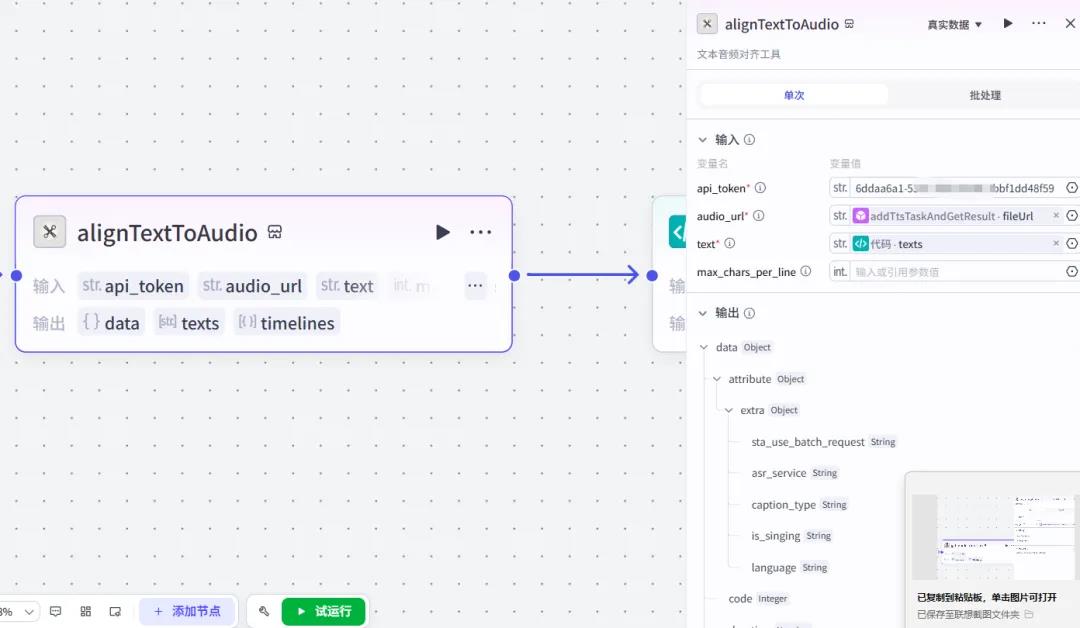
使用代码节点,随机选取我们准备好的视频素材,此处需要根据字幕时间来计算使用多少个视频片段。
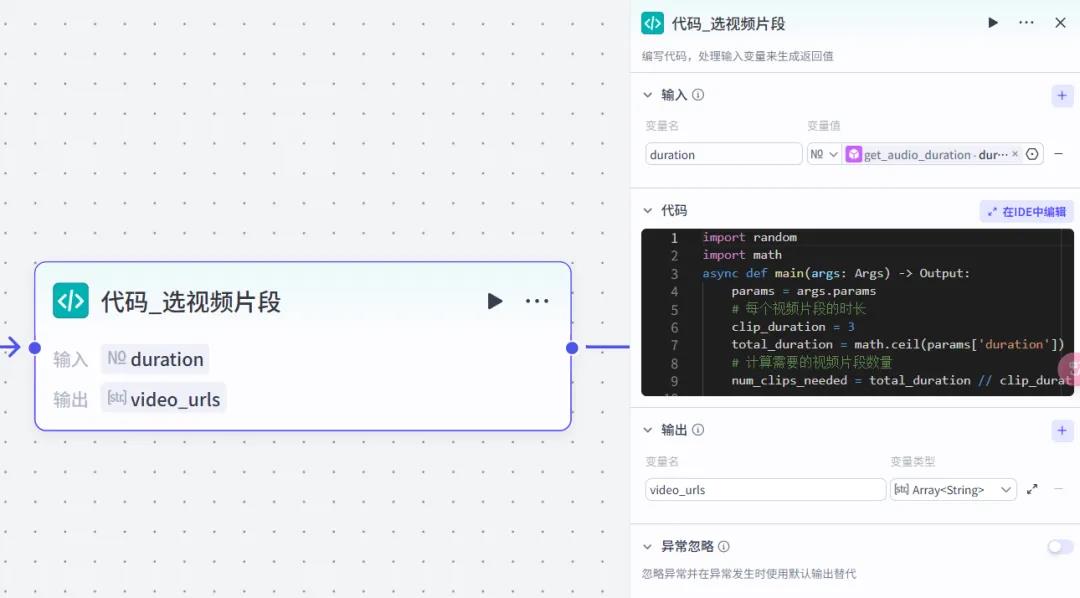
然后使用代码节点,对准备好的素材数据进行组合。
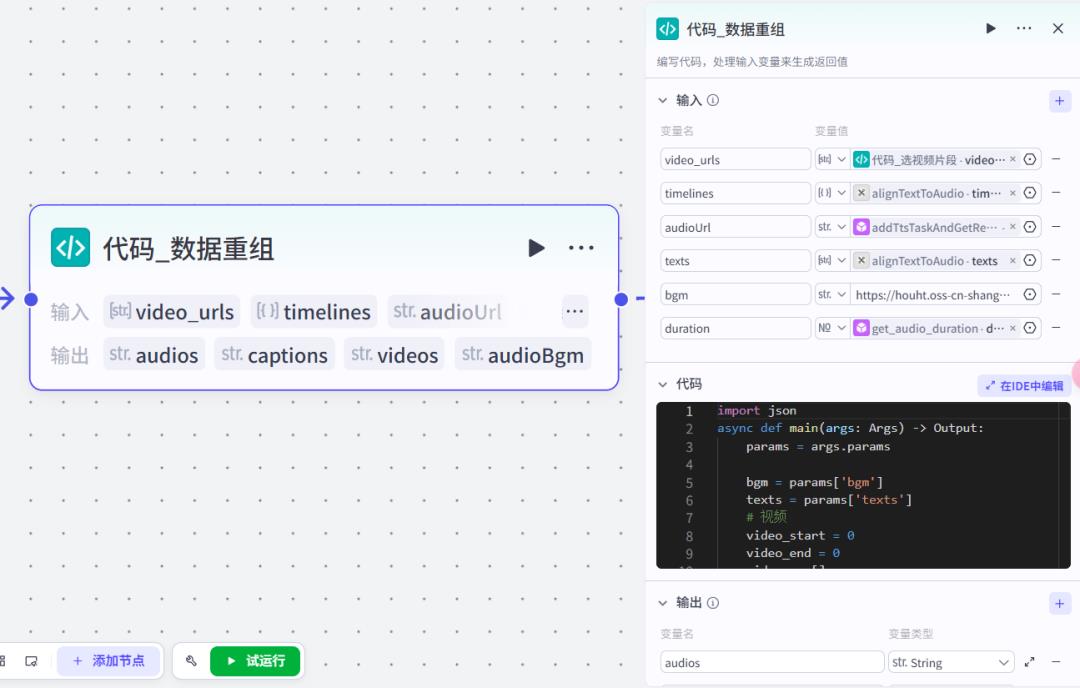
import json
asyncdefmain(args: Args) -> Output:
params = args.params
bgm = params['bgm']
texts = params['texts']
# 视频
video_start = 0
video_end = 0
videos = []
for item in params['video_urls']:
video_end = video_start + 3*1000000
videos.append({
"video_url": item,
"duration": 3*1000000,
"start": video_start,
"end": video_end,
"width":576,
"height":1024,
"transition": "叠化",
"transition_duration": 1000000
})
if video_end >video_start:
video_start = video_end
# 背景音乐
audioBgm = [{
"audio_url": bgm,
"start": 0,
"end": video_end
}]
#配音、字幕
start = 0
end = 0
captions = []
audios = []
audios.append({
"audio_url": params['audioUrl'],
"duration": params['duration']*1000000,
"start": 0,
"end": params['duration']*1000000
})
timelines = params['timelines']
for idx,item inenumerate(timelines):
start = item['start']
end = item['end']
text = texts[idx]
captions.append({
'text': text,
'start': start,
'end': end,
"in_animation":"渐显","out_animation":"渐隐"
})
# 构建输出对象
ret = {
"captions": json.dumps(captions),
"audios": json.dumps(audios),
"videos": json.dumps(videos),
"audioBgm": json.dumps(audioBgm)
}
return ret最后串联剪映小助手插件,生成视频
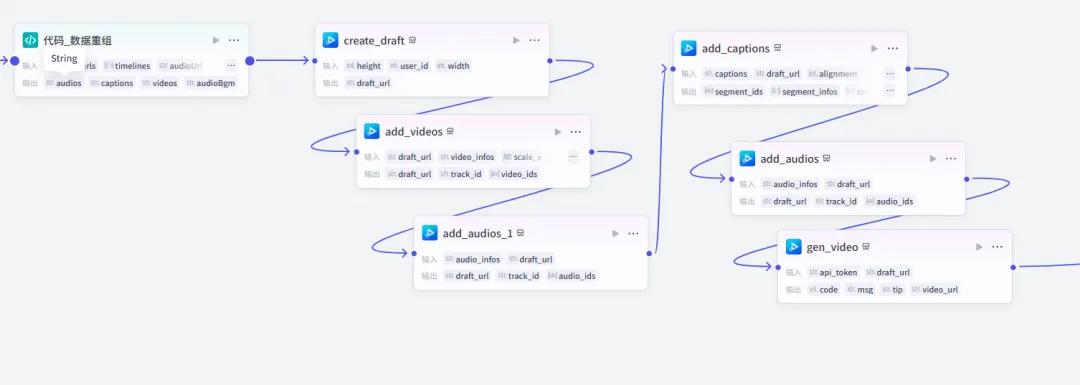
此处需要注意的是,根据自己的要求单独设置字幕字体位置、颜色等参数。
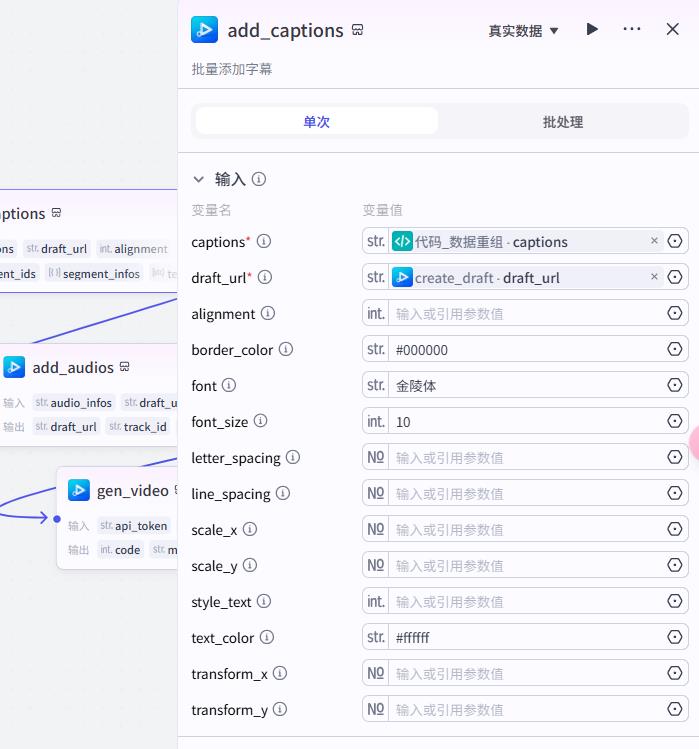
最后到这里我们的国学文化混剪工作流就全部完成了,这次操作很简单,但是效果也很好,希望大家多多点赞收藏评论哦。
原创文章,作者:小肥鱼网创,如若转载,请注明出处:https://www.xfywc.com/41885.html